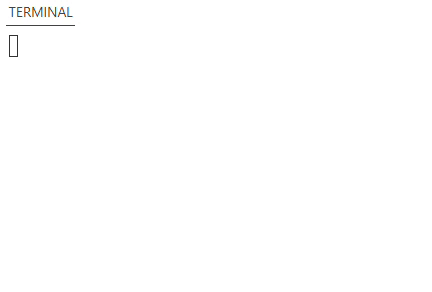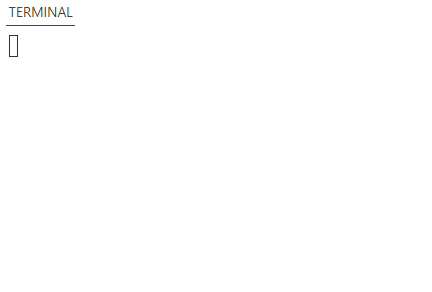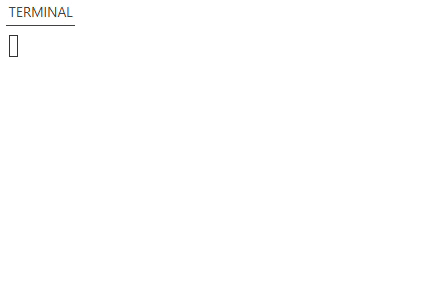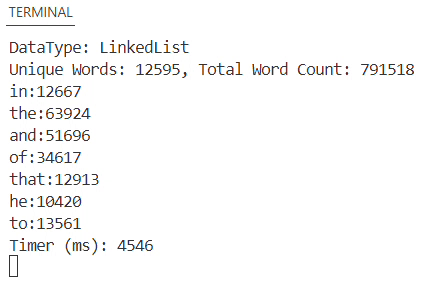Click Here for Project Repository
This project, undertaken for my Elementary Data Structures and Algorithms class, involved developing a Java-based text parser to analyze the complete text of the Bible. The core objective was to compare the efficiency of different data structures (like linked lists and hash map) in counting the frequency of each unique word.


The challenge lay in efficiently processing a large text file and accurately counting the occurrences of each unique word. This required careful consideration of data structure choices and algorithmic implementation to optimize for speed and memory usage.